Example 2. Alloying elements in recycling.
ODYM example by Stefan Pauliuk, adapted for flodym
A recycling system with two end-of-life (EoL) products, two scrap types, one secondary material, and several types of losses are studied. Three chemical elements are considered: iron, copper, and manganese. A time horizon of 30 years [1980-2010], five processes, and time-dependent parameters are analysed. The processes have element-specific yield factors, meaning that the loss rates depend on the chemical element considered. These values are given below.
The research questions are:
How much copper accumulates in the secondary steel assuming that all available scrap is remelted?
How much manganese is lost in the remelting process assuming that all available scrap is remelted?
What is more effective in reducing the copper concentraction of secondary steel: A reduction of the shredding yield factor for copper from EoL machines into steel scrap of 25% or an increase in the EoL buildings flow by 25%? (All other variables and parameters remaining equal)
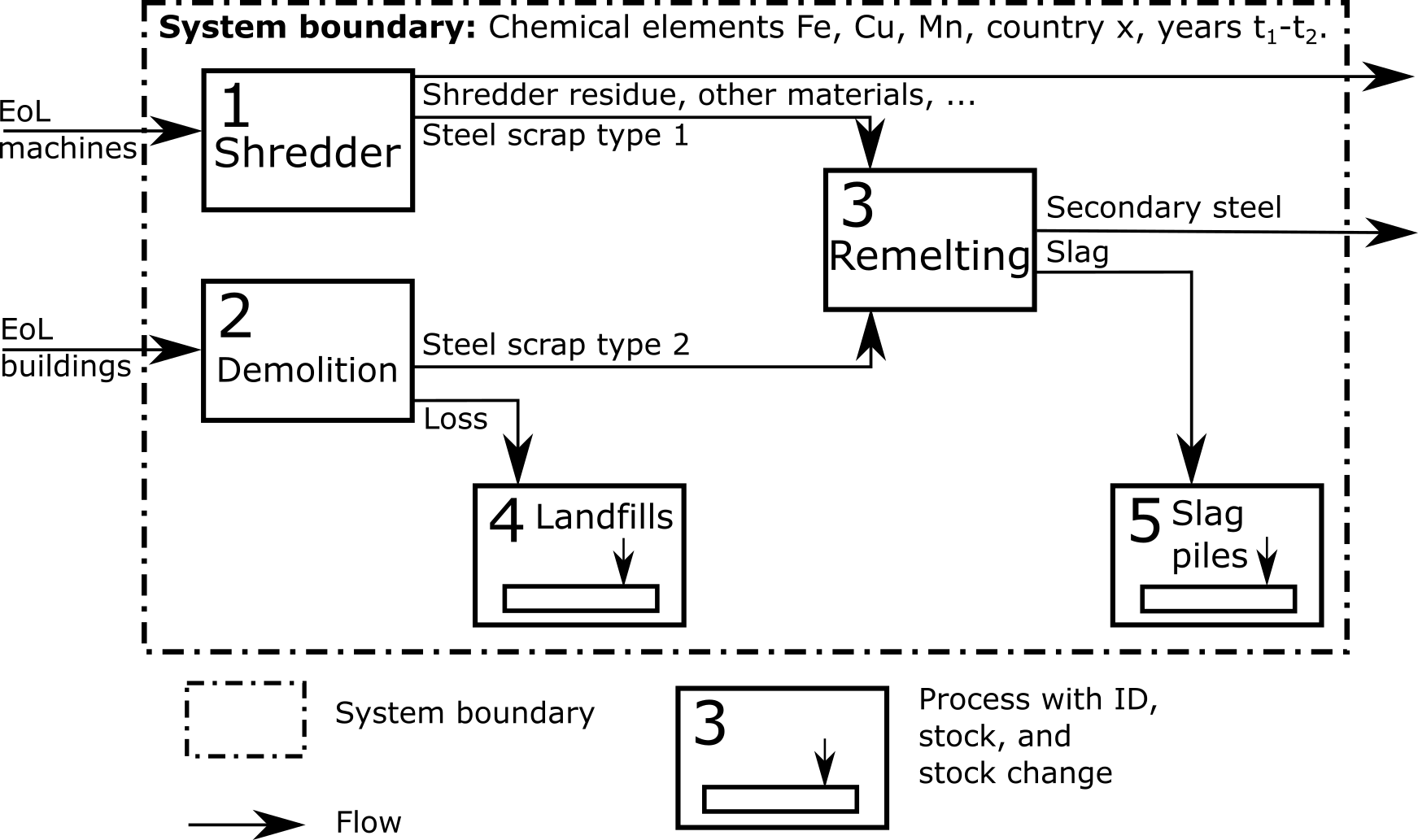
The model equations are as follows:
\(F_{1\_3}(t,e) = \Gamma_1(e) \cdot F_{0\_1}(t,e)\) (shredder yield factor)
\(F_{1\_0}(t,e) = (1 - \Gamma_1(e)) \cdot F_{0\_1}(t,e)\) (mass balance)
\(F_{2\_3}(t,e) = \Gamma_2(e) \cdot F_{0\_2}(t,e)\) (demolition yield factor)
\(F_{2\_4}(t,e) = (1 - \Gamma_2(e)) \cdot F_{0\_2}(t,e)\) (mass balance)
\(F_{3\_0}(t,e) = \Gamma_3(e) \cdot (F_{1\_3}(t,e)+F_{2\_3}(t,e))\) (remelting yield factor)
\(F_{3\_5}(t,e) = (1 - \Gamma_3(e)) \cdot (F_{1\_3}(t,e)+F_{2\_3}(t,e))\) (mass balance)
Here the index letters t denote the model time and e the chemical element.
1. Load flodym and other useful packages
[28]:
import os
from copy import deepcopy
import numpy as np
import plotly.io as pio
from flodym import (
MFADefinition,
DimensionDefinition,
ParameterDefinition,
FlowDefinition,
StockDefinition,
MFASystem,
SimpleFlowDrivenStock,
)
from flodym.export import PlotlyArrayPlotter
# needed only for correct rendering on the readthedocs homepage
pio.renderers.default = "browser"
2. Define the data requirements, flows, stocks and MFA system equations
We define the dimensions that are relevant for our system and the model parameters, processes, stocks and flows. We put it all together in an MFADefinition object.
[29]:
dimension_definitions = [
DimensionDefinition(letter="t", name="Time", dtype=int),
DimensionDefinition(letter="e", name="Material", dtype=str),
]
parameter_definitions = [
ParameterDefinition(name="eol machines", dim_letters=("t",)),
ParameterDefinition(name="eol buildings", dim_letters=("t",)),
ParameterDefinition(name="composition eol machines", dim_letters=("e",)),
ParameterDefinition(name="composition eol buildings", dim_letters=("e",)),
ParameterDefinition(name="shredder yield", dim_letters=("e",)),
ParameterDefinition(name="demolition yield", dim_letters=("e",)),
ParameterDefinition(name="remelting yield", dim_letters=("e",)),
]
[30]:
process_names = [
"sysenv",
"shredder",
"demolition",
"remelting",
"landfills",
"slag piles",
]
[31]:
flow_definitions = [
FlowDefinition(from_process_name="sysenv", to_process_name="shredder", dim_letters=("t", "e")),
FlowDefinition(
from_process_name="sysenv", to_process_name="demolition", dim_letters=("t", "e")
),
FlowDefinition(
from_process_name="shredder",
to_process_name="remelting",
dim_letters=("t", "e"),
), # scrap type 1
FlowDefinition(
from_process_name="shredder", to_process_name="sysenv", dim_letters=("t", "e")
), # shredder residue
FlowDefinition(
from_process_name="demolition",
to_process_name="remelting",
dim_letters=("t", "e"),
), # scrap type 2
FlowDefinition(
from_process_name="demolition",
to_process_name="landfills",
dim_letters=("t", "e"),
), # loss
FlowDefinition(
from_process_name="remelting",
to_process_name="slag piles",
dim_letters=("t", "e"),
), # secondary steel
FlowDefinition(
from_process_name="remelting", to_process_name="sysenv", dim_letters=("t", "e")
), # slag
]
[32]:
stock_definitions = [
StockDefinition(
name="landfills",
process="landfills",
dim_letters=("t", "e"),
subclass=SimpleFlowDrivenStock,
),
StockDefinition(
name="slag piles",
process="slag piles",
dim_letters=("t", "e"),
subclass=SimpleFlowDrivenStock,
),
]
[33]:
mfa_definition = MFADefinition(
dimensions=dimension_definitions,
parameters=parameter_definitions,
processes=process_names,
flows=flow_definitions,
stocks=stock_definitions,
)
We define a MFASystem subclass with our system equations in the compute method. We just need to define the compute method with our system equations, as all the other things we need are inherited from the MFASystem class. The flow names are generated from the processes each flow connects, in this case with the naming function process_names_with_arrow, which is passed to the flow initialization below.
[34]:
class SimpleMFA(MFASystem):
def compute(self):
self.flows["sysenv => shredder"][...] = (
self.parameters["eol machines"] * self.parameters["composition eol machines"]
)
self.flows["sysenv => demolition"][...] = (
self.parameters["eol buildings"] * self.parameters["composition eol buildings"]
)
self.flows["shredder => remelting"][...] = (
self.flows["sysenv => shredder"] * self.parameters["shredder yield"]
)
self.flows["shredder => sysenv"][...] = self.flows["sysenv => shredder"] * (
1 - self.parameters["shredder yield"]
)
self.flows["demolition => remelting"][...] = (
self.flows["sysenv => demolition"] * self.parameters["demolition yield"]
)
self.flows["demolition => landfills"][...] = self.flows["sysenv => demolition"] * (
1 - self.parameters["demolition yield"]
)
self.flows["remelting => sysenv"][...] = (
self.flows["shredder => remelting"] + self.flows["demolition => remelting"]
) * self.parameters["remelting yield"]
self.flows["remelting => slag piles"][...] = (
self.flows["shredder => remelting"] + self.flows["demolition => remelting"]
) * (1 - self.parameters["remelting yield"])
self.stocks["landfills"].inflow[...] = self.flows["demolition => landfills"]
self.stocks["landfills"].compute()
self.stocks["slag piles"].inflow[...] = self.flows["shredder => remelting"]
self.stocks["slag piles"].compute()
4. Initialize the MFA system, load data and compute
We now have all the necessary information. We load the data (dimension items and parameter values) from excel files and initialize the MFA system in one step. We then execute the compute method to calculate the system.
[35]:
dimension_file = os.path.join("input_data", "example2_dimensions.xlsx")
parameter_file = os.path.join("input_data", "example2_parameters.xlsx")
mfa_example = SimpleMFA.from_excel(
definition=mfa_definition,
dimension_files={d.name: dimension_file for d in dimension_definitions},
parameter_files={p.name: parameter_file for p in parameter_definitions},
dimension_sheets={d.name: d.name for d in dimension_definitions},
parameter_sheets={p.name: p.name for p in parameter_definitions},
)
mfa_example.compute()
5. Results
Here we answer the research questions from the beginning of the notebook.
How much copper accumulates in the secondary steel assuming that all available scrap is remelted?
Clicking on the Fe entry of the plot legend hides it and adjusts the y-axis to better display the trace elements Mn and Cu.
[36]:
remelted = mfa_example.flows["remelting => sysenv"]
plotter = PlotlyArrayPlotter(
array=remelted,
intra_line_dim="Time",
linecolor_dim="Material",
title="GDP-per-capita",
)
fig = plotter.plot(do_show=True)
[37]:
remelted_shares = remelted.get_shares_over(("e",))
plotter = PlotlyArrayPlotter(
array=remelted_shares,
intra_line_dim="Time",
linecolor_dim="Material",
title="Share of copper and manganese in secondary steel",
)
fig = plotter.plot(do_show=True)
The copper flow in the secondary steel increases linearly from 0.34 kt/yr in 1980 to 0.78 kt/yr in 2010. The concentration of copper declines in a hyperbolic curve from 0.294% in 1980 to 0.233% in 2010.
That concentration is below 0.4% at all times, the latter being the treshold for construction grade steel, but above 0.04%, which is the threshold for automotive steel.
How much manganese is lost in the remelting process assuming that all available scrap is remelted?
[38]:
manganese_to_slag = mfa_example.flows["remelting => slag piles"]["Mn"]
plotter = PlotlyArrayPlotter(
array=manganese_to_slag,
intra_line_dim="Time",
ylabel="kt/yr",
title="Manganese lost in the remelting process",
)
fig = plotter.plot(do_show=True)
What is more effective in reducing the copper concentraction of secondary steel: A reduction of the shredding yield factor for copper from EoL machines into steel scrap of 25% or an increase in the EoL buildings flow by 25%? (All other variables and parameters remaining equal)
To answer this we change the parameter values and recalculate the entire system. In case a, we update the shredder yield, and in case b we increase the EoL buildings flow. We could load new datasets for the parameters, but since we are only changing one value, we will just update that value.
[39]:
mfa_example_a = deepcopy(mfa_example)
mfa_example_a.parameters["shredder yield"].set_values(np.array([0.92, 0.075, 0.92]))
mfa_example_a.compute()
shares_shredder = mfa_example_a.flows["remelting => sysenv"].get_shares_over(("e"))
[40]:
mfa_example_b = deepcopy(mfa_example)
mfa_example_b.parameters["eol buildings"][...] *= 1.25
mfa_example_b.compute()
shares_demolition = mfa_example_b.flows["remelting => sysenv"].get_shares_over(("e"))
[41]:
plotter = PlotlyArrayPlotter(
array=remelted_shares,
intra_line_dim="Time",
subplot_dim="Material",
line_label="Standard",
title="Material concentration in secondary steel",
)
fig = plotter.plot()
plotter = PlotlyArrayPlotter(
array=shares_shredder,
intra_line_dim="Time",
subplot_dim="Material",
line_label="Updated shredder yield",
fig=fig,
)
fig = plotter.plot()
plotter = PlotlyArrayPlotter(
array=shares_demolition,
intra_line_dim="Time",
subplot_dim="Material",
line_label="Increased buildings demolition",
fig=fig,
)
fig = plotter.plot(do_show=True)
We can see that both measures reduce the copper concentration in the secondary steel. For the first year, the copper concentration is reduced from 0.294% to 0.244% if the Cu-yield into steel scrap of the shredder is reduced and to 0.259% if the EoL building flow treated is increased by 25%. The yield measure thus has a slightly higher impact on the copper contentration than the increase of a copper-poor scrap flow for dilution. In both cases the impact is not high enough to bring the copper concentration to values below 0.04%, which is necessary for automotive applications.
[ ]: